-
[SQLD] SQL 개발자 공부하기 Day 15 : 과목별 핵심 150제 오답노트 (2/3)Study/SQL 2024. 3. 1. 23:44728x90반응형
목차
1. 과목별 핵심 150제 오답노트 (2/3)

이기적 SQL 개발자 이론서 + 기출문제 문제집을 풀었고,
SQLD 과목별 핵심 150제 중 50문제를 풀었다.
SQL 기본 및 활용 50문제 중 20문제를 틀렸다.오답 풀이
SQL 기본 및 활용
51. 비용 기반 옵티마이저는 적절한 인덱스가 존재한다고 반드시 인덱스를 사용하는 것은 아니다.
‣ 옵티마이저는 SQL 실행 계획을 수립하고 실행하는 소프트웨어이다.
‣ 옵티마이저는 질의에 대해 실행 계획을 생성한다.
‣ 비용 기반 옵티마이저는 비용을 기반으로 최적의 작업을 수행한다. 따라서, 인덱스 스캔보다 전체 테이블 스캔이 비용이 낮다고 판단하‣면 적절한 인덱스가 존재하더라도 전체 테이블 스캔으로 SQL문을 수행할 수 있다.
‣ 비용 기반 옵티마이저는 비용 계산을 위해 다양한 통계정보를 사용한다.
‣ 규칙 기반 옵티마이저에서 제일 낮은 우선순위는 전체 테이블 스캔이다.52. 동일 SQL문에 대해 실행 계획이 다르다고 결과가 달라지지는 않는다.
‣ 실행 계획이 달라지지는 않지만, 성능이 달라질 수는 있다.
‣ 실행 계획은 SQL문의 처리를 위한 절차와 방법이 표현된다.
‣ 실행 계획은 액세스 기법, 조인 순서, 조인 방법 등으로 구성된다.
‣ 최적화 정보는 실행 계획의 단계별 예상비용을 표시한 것이다.53. SQL 처리 흐름도에서는 성능적인 측면도 표현할 수 있다.
‣ SQL 처리흐름도는 실행 계획을 시각화한 것이다.
‣ SQL 처리흐름도는 일량적인 측면의 표현과 인덱스 스캔 또는 전체 테이블 스캔 등을 표현할 수 있다.59. 다음 SQL 문을 설명하라.


‣ SELECT 문에 WHERE 조건이 없으므로 연산에 참여하는 총 행 수는 5개이다.
‣ DEPTNO 10의 합계는 3000이고 20의 합계는 500이다.
‣ 그룹 함수를 사용하는 경우 NULL 값은 연산에서 제외된다.
‣ 부서별 합계를 계산할 때 NULL을 만나면 0으로 치환한다.반응형62. GROUP BY CUBE(DEPTNO, JOB); 과 동일한 결괏값을 반환하는 그룹 함수는 GROUP BY GROUPING SETS ( DEPTNO, JOB, (DEPTNO, JOB), ()); 이다.
그룹함수
‣ ROLLUP은 칼럼에 대한 Subtotal
‣ GROUPING은 합계값이 계산되면 1을 반환
‣ GROUPING SETS은 칼럼 순서와 관계없이 다양한 소계
‣ CUBE는 결합 가능한 모든 집계 계산73. 다음의 결괏값을 보고 SQL문을 만들어 보아라.

SELECT DEPTNO, JOB, SUM(SAL)
FROM 표이름
GROUP BY ROLLUP(DEPTNO, JOB);74. DEPARTMENT_ID의 값이 [NULL, 10, 20, 30, 40, 50, 220, 230]이다.
SELECT DISTINCT DEPARTMENT_ID FROM HR.EMPLOYEES A WHERE A.DEPARTMENT_ID <= ALL (30, 50);
다음 SQL문의 실행 결과는?
[10, 20, 30]
ALL 연산자는 서브쿼리 값 모두가 조건에 만족해야 한다. 그러므로 30 이하인 값을 찾으면 되고 NULL 값은 제외한다.78. 다음 테이블은 EMP, DEPT 테이블이다.


SELECT DNAME, JOB, COUNT(*) "Total EMP", SUM(SAL) "Total SAL"
FROM SCOTT.EMP A, SCOTT.DEPT B
WHERE A.DEPTNO = B.DEPTNO
GROUP BY CUBE(DNAME,JOB);다음과 같은 SQL문을 사용했을 시, ROWS의 개수는 어떻게 되는가?
총 18개.
DEPT 합계, JOB 합계, (DEPT와 JOB) 합계, 전체합계를 나타낸다.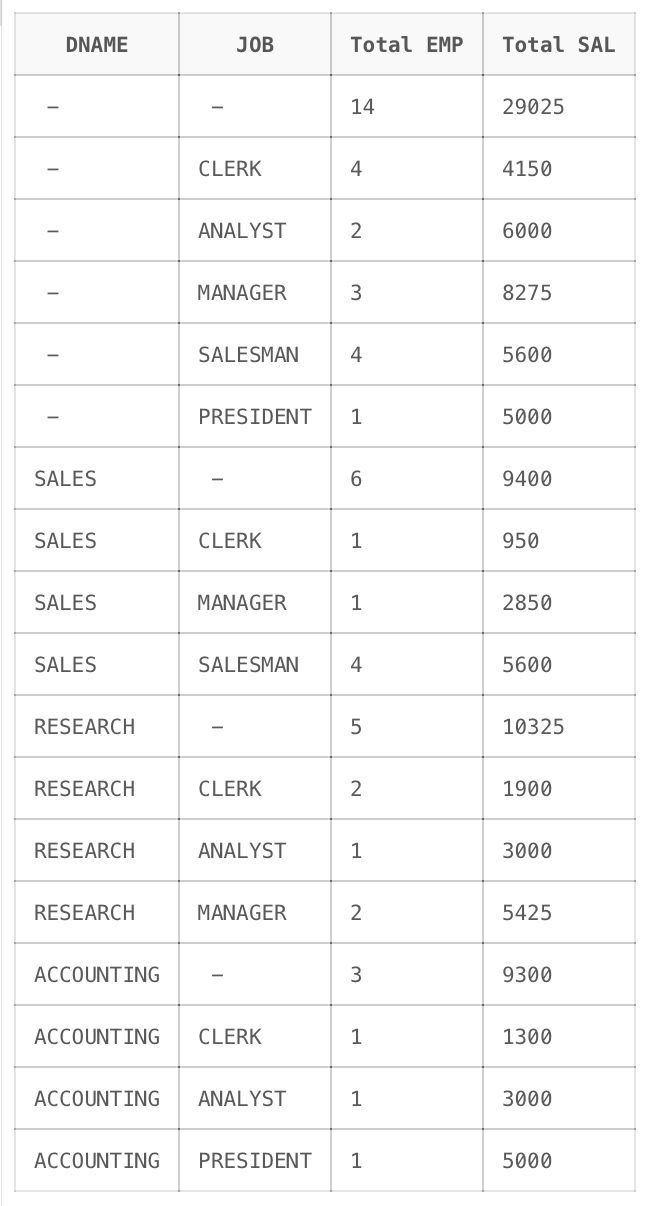
81. to_char( ) 함수로 인덱스 키 칼럼을 형변환하면 인덱스를 사용할 수 없다.
인덱스가 있어도 인덱스 칼럼에 형변환이 발생하면 인덱스를 사용할 수 없다.
82. 사원번호는 기본키, 사원번호 1번을 검색하는데 사원 테이블에는 하나의 ROW만 저장되어 있다면 유리한 스캔 방법은 Table Full Scan이다.
하나의 데이터(행)를 읽기 위해서는 인덱스를 사용하지 않고 테이블을 FULL SCAN하는 것이 효율적이다.
84. Nested Loop 방식의 조인 절차는?
1) 선행 테이블에서 조건을 만족하는 첫 번째 행을 찾는다.
2) 선행 테이블의 조인 키를 가지고 후행 테이블에 조인 키가 존재하는지 찾으러 가서 조인을 시도한다.
3) 후행 테이블의 인덱스에 선행 테이블의 조인 키가 존재하는지 확인한다.
4) 인덱스에서 추출한 레코드 식별자를 이용하여 후행 테이블을 액세스 한다.85. 기본키와 외래키 관계에서 외래키에 인덱스가 없을 때, Nested Loop 방식 조인보다 Sort Merge 방식의 조인이 효율적이다.
‣ Sort Merge 방식은 두 테이블의 크기가 비슷하고, 정렬이 이미 되어 있거나 정렬 비용이 크지 않을 때 효율적이다. 대용량 데이터를 다룰 때 유리할 수 있으며, 인덱스가 없는 테이블 간의 조인에 자주 사용된다.
‣ Nested Loop 방식은 하나의 테이블이 작고 다른 하나가 큰 경우, 또는 작은 테이블에 적절한 인덱스가 있을 때 효율적이다. 두 테이블의 크기 차이가 클 때 유용하며, 내부 테이블에 적절한 인덱스가 있을 경우 성능이 향상된다.86. [Select empno, ename from emp where empno=1;] 다음 SELECT문에서 Table을 탐색하지 않고 Fetch 하려고 할 때, Index 생성문은 어떻게 작성해야 할까?
... 잘 이해가 안 간다
728x9087. [SELECT E.이름 FROM 직원 AS E WHERE E.직원번호 LIKE (SELECT 직원번호 FROM 부양가족 WHERE E.성별 = 성별);] SQL문은 LIKE 대신에 IN이 들어가야 한다.
88. 이것도 이해가 안 된다..
90. [SELECT * FROM EMP WHERE EMP_NAME LIKE 'A%';]는 테이블의 EMP_NAME이 A로 시작하는 모든 ROW를 나타낸다.
'A%'은 A와 a가 아닌 A로 시작하는 값을 찾는다.
92. 부양가족을 2명 이상 가진 사원의 사번(eno), 성명(ename), 부양가족 수를 검색하는 sql문을 작성해라.
employee(eno, ename, adddress, score, dno) / dependent(eno, ename, birthday, relation)
Select e.eno, e.ename, t.cnt
From employee e, (select eno, count(*), as cnt From dependent GROUP BY eno Having count(*) >= 2) t
WHERE e.eno = t.eno;93. 인덱스 튜닝은 책에서 안 나왔던 거 같다.
95. [SELECT COALESCE(NULL,'2','1') From DUAL;]의 결과는?
2
COALESCE 함수는 NULL이 아닌 첫 번째 값을 반환한다.96. [SELECT * FROM dual WHERE NULL = NULL;]의 결과는?
NULL과 NULL을 비교하면 공집합을 되돌린다. 즉 아무런 결과가 나오지 않는다.
728x90반응형'Study > SQL' 카테고리의 다른 글
[SQLD] SQL 개발자 공부하기 Day 17 : 최신 기출문제 1회 오답노트 (0) 2024.03.04 [SQLD] SQL 개발자 공부하기 Day 16 : 과목별 핵심 150제 오답노트 (3/3) (0) 2024.03.03 [SQLD] SQL 개발자 공부하기 Day 14 : 과목별 핵심 150제 오답노트 (1/3) (1) 2024.02.29 [SQLD] SQL 개발자 공부하기 Day 13 : SQL 기본 및 활용 오답노트 (0) 2024.02.28 [SQLD] SQL 개발자 공부하기 Day 12 : DML / DCL / TCL (1) 2024.02.27