-
정말 그 기능 덕분일까? - 기획자를 위한 인과추론 입문Study/서비스기획 2025. 6. 17. 13:05728x90반응형
📌 개요
우리는 서비스를 설계하거나 개선할 때 자주 이런 질문을 합니다.
- 왜 전환율이 떨어졌지?
- 알림을 바꿨더니 방문자가 늘어난 이유는 무엇일까?
- 정말 A를 했기 때문에, B가 일어난 걸까?
이처럼 어떤 결과의 진짜 원인을 알고 싶을 때, 필요한 게 바로 '인과추론'입니다.
🔍 인과추론이란
어떤 현상(결과)이 왜 일어났는지(원인), 그 관계를 찾아내는 과정입니다.
단순히 “함께 일어났다”는 상관관계가 아니라 “이것 때문에 저것이 발생했다”는 인과관계를 말합니다.
Evidence(어떤 현상에 대한 근거)를 기반으로, 진짜 원인을 식별하는 것이 핵심입니다.
예시)
- 상관관계 : 얼음 판매량이 늘어날수록 익사 사고도 늘어난다.
- 인과관계 : 여름이 되면서, 더운 날씨로 얼음 수요와 수영 활동이 증가했고, 수영 활동 증가로 익사 사고도 증가했다.
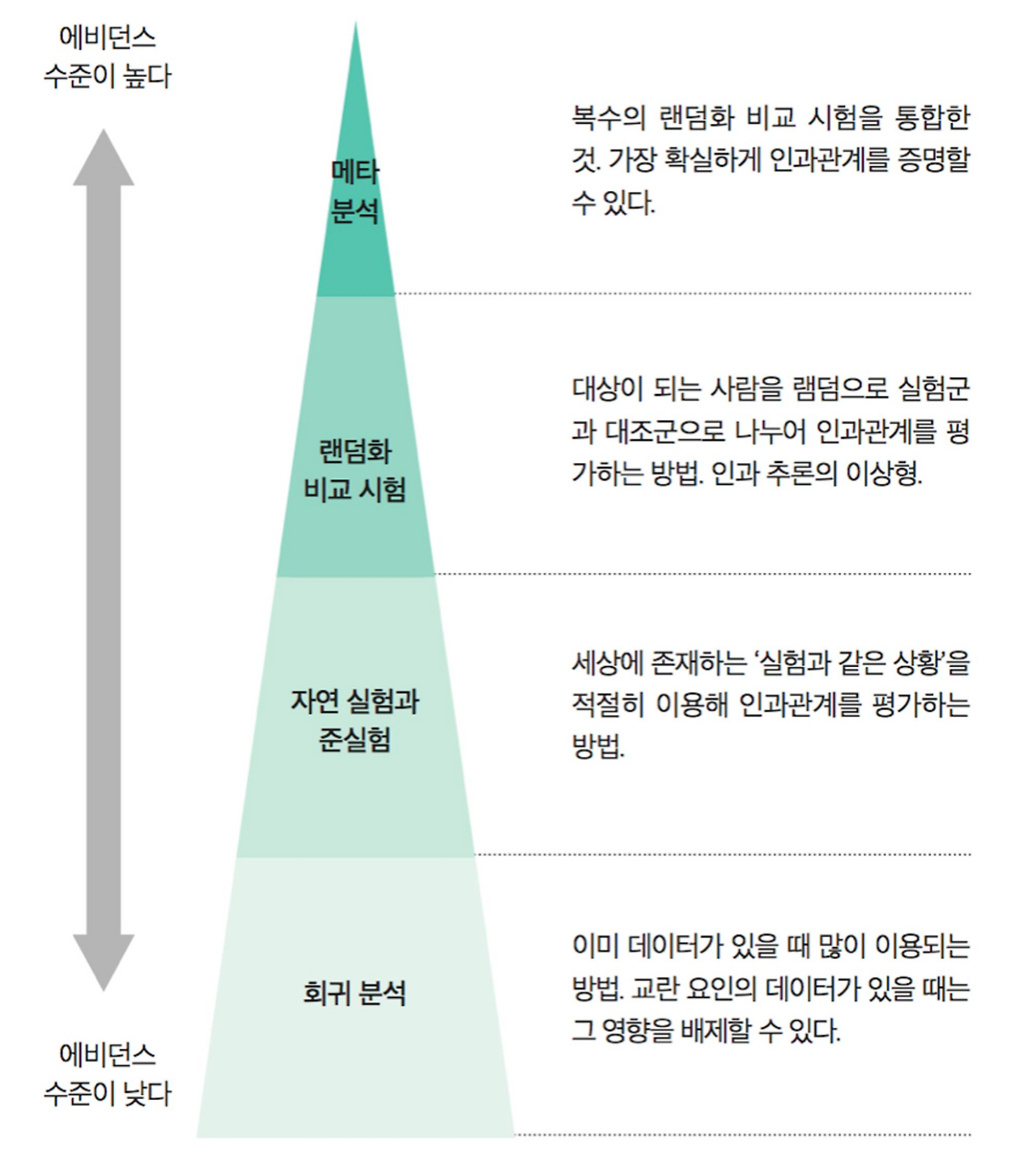
🔍 인과를 추론할 수 있는 대표적인 방법
 반응형
반응형1. 메타 분석 (Meta-analysis)
동일하거나 유사한 주제를 다룬 여러 독립적인 연구 결과를 통계적으로 통합해 분석하는 방법입니다.
가장 확실하게 인과관계를 증명할 수 있으며, 가장 신뢰도가 높은 방법입니다.
단, 이미 다수의 연구가 존재하는 경우에만 사용이 가능합니다.
사용자 연구와 사례 분석이 많이 축적되었을 때 활용할 수 있습니다.
예시)
UX Writing 개선 효과를 분석한 15개의 연구 결과를 통합하여,
CTA 버튼 문구 변경이 평균적으로 전환율에 얼마나 영향을 주는지 파악2. 랜덤화 비교 시험 (Randomized Controlled Trials, RCT)
실험군과 대조군을 무작위로 나누어 인과관계를 평가하는 방법입니다.
가장 이상적인 인과 추론 방식에 해당되며, 우리가 흔히 아는 A/B 테스트도 이 방법에 해당합니다.
예시)
커머스 앱에서 A 그룹은 배송비 무료 배너,
B 그룹은 일반 배너를 노출해 전환율 차이를 실험3. 자연 실험 (Natural Experiment), 준실험 (Quasi-Experiments)
세상에 자연스럽게 발생한 '실험 같은 상황'을 적절히 이용해 인과관계를 평가하는 방법입니다.
제도 변경, 정책 시행, 자연재해 등 외부 요인 덕분에 실험군과 통제군이 우연히 나뉜 상황에서 비교할 수 있습니다.
728x90방법 1 : 이중차분법 (DID)
시간 흐름에 따른 전후 차이와 집단 간 차이를 동시에 고려하여 특정 개입의 효과를 추정하는 방법입니다.
단, DID 방법론을 적용하려면 '평행 추세 가정(Parallel Trends Assumption)'이 반드시 만족해야 합니다.
만약 개입이라는 사건이 없었다면, 실험군과 통제군이 시간이 지남에 따라 비슷한 추세를 보였어야 합니다.
이 조건이 충족되지 않는다면, DID를 통해 계산된 효과 추정치는 편향될 위험이 있습니다.
예시)
어떤 지역에만 시범적으로 전자 세금계산서 기능을 먼저 적용했을 때,
적용 전후 회계업무 시간 감소 효과를 다른 지역과 비교해 파악.방법 2 : 매칭법
분석의 결과에 영향을 줄 공변량(Confounding Variables)을 활용하여, 대조군에서 실험군과 최대한 유사한 특성을 가진 샘플을 찾아 짝지은 다음 서로 비교하는 방법입니다.
현실적으로 모든 조건이 같은 대조군을 찾는 것을 불가능하기 때문에, 실무에서는 ‘성향 점수 매칭법(Propensity Score Matching)’을 주로 사용합니다.
예시)
신규 알림 기능을 사용한 유저와 사용하지 않은 유저 간 이탈률을 비교
단, 둘의 기존 활동성/결제력 수준이 유사하도록 성향 점수로 매칭4. 회귀 분석 (Regression Analysis)
다양한 변수들이 결과에 미치는 영향을 통계적으로 분석하는 방법입니다.
이미 수집된 데이터가 있을 때 많이 이용되는 방법입니다.
교란 요인의 데이터가 있을 때는 그 영향을 배제할 수 있습니다.
완전한 인과를 증명하기 어렵지만, 강한 추정 도구로 자주 사용됩니다.
예시)
‘주간 사용 시간’, ‘결제 경험’, ‘마케팅 알림 클릭 수’ 등의 변수가
앱 내 특정 행동(예: 구독 전환)에 미치는 영향을 수치로 분석
💡 배운점
✅ 기획은 무엇이 효과를 냈는가를 알아야 반복할 수 있고, 무엇이 실패였는지 알아야 개선할 수 있다.
✅ 단순히, 지표의 변화만 보고 판단하는 건 위험하다. 수치는 결과다. 진짜 중요한 건 그 결과를 만든 행동과 맥락의 연결고리다.
✅ 의사결정 과정에서 "정말 이것 때문에 저게 일어난 걸까?"를 묻고, 그 근거를 찾는 습관이 필요하다.
728x90반응형'Study > 서비스기획' 카테고리의 다른 글
Home 화면은 사용자의 거실이다. - 토스는 왜 토스머니를 없앴을까? (4) 2025.06.05 UX 리서치는 진찰이다. - 사용자가 어디가 아픈지 탐색하는 과정 (2) 2025.05.30 검색에서 탐색으로 가는 여정 - 네이버지도와 카카오맵 검색 비교 분석 (1) 2025.05.26 같은 길, 다른 UX - 네이버지도와 카카오맵 홈 화면 비교 분석 (5) 2025.05.19 좋은 지표, 나쁜 경험 (Simplicity 24) - 지표는 성공인데, 사용자는 불편해했다 (1) 2025.05.12